얼마 전 분기없이 작성한 퀵정렬이 최대 80% 가량의 성능향상을 가져온다는 글을 보았다.
https://arxiv.org/abs/1604.06697
기본적인 아이디어는 branch를 쓰지 않고,
setcc와 cmov같은 Conditional Move를 사용한다는 것이다.
그런데 생각을 해보면..
Branch와 Conditional Move가 뭐가 다를까?
- 어차피 setcc와 cmov도 비교(cmp) 가 끝날 때 까지 파이프라인 stall이 걸린다.
- cmov는 History가 기록되지 않는가?
- cmov는 투기적 실행을 하지 않는가?
인텔 메뉴얼을 살펴보자.
(Intel 64 and IA-32 Architecture Optimization Reference Manual, 2016. Order Number:
248966-032.)
• It reduces the possibility of mispredictions.
• It reduces the number of required branch target buffer (BTB) entries.
Conditional branches that are never taken do not consume BTB resources.
Branch Target Buffer를 CMOV는 사용하지 않는단다.
즉 History를 CMOV는 저장을 안한다.
그러면?
- cmov는 투기실행을 하지 않는다. (hitory 없음)
- cmov는 cmp가 끝날 때 까지 대기한다.
아하.
이러면 branch와 cmov는 써야 할 상황이 갈린다.
Branch Prediction을 사용하는 이유는,
대다수 프로그램에서 한 쪽 방향으로 분기할 확률이 높기 때문이다.
하지만 예측 불가능한 분기, 평균적으로 분기 확률이 50%라면?
분기예측은 자주 실패한다.
분기예측 실패는 분기예측을 하지 않는 것 보다 비용이 크다.
즉 분기를 예측할 수 없다면 분기예측을 하지 않고 cmp를 기다리는게 더 빠르다.
이게 cmov인 것이다.
cmp 결과가 관측될 때 까지 그냥 대기한다.
정렬 알고리즘은 편향된 데이터가 아니라면 보통 분기를 예측할 수 없다.
그러니 정렬에서 분기예측을 빼면 랜덤한 데이터에서
분기예측 실패로 인한 파이프라인 플러시 비용을 없앨 수 있다.
결론
- 편향적 분기가 예상되면 그냥 일반 분기로 작성한다.
- 예측불가한 분기가 예상되면 비트연산등을 써서 분기를 없애본다. (abs()같은거 디스어셈블리 해보면 분기 없이 비트연산을 쓴다)
- 비트연산을 사용할 수 없다면 cmov나 setcc같은 Conditional Branch 를 쓴다.
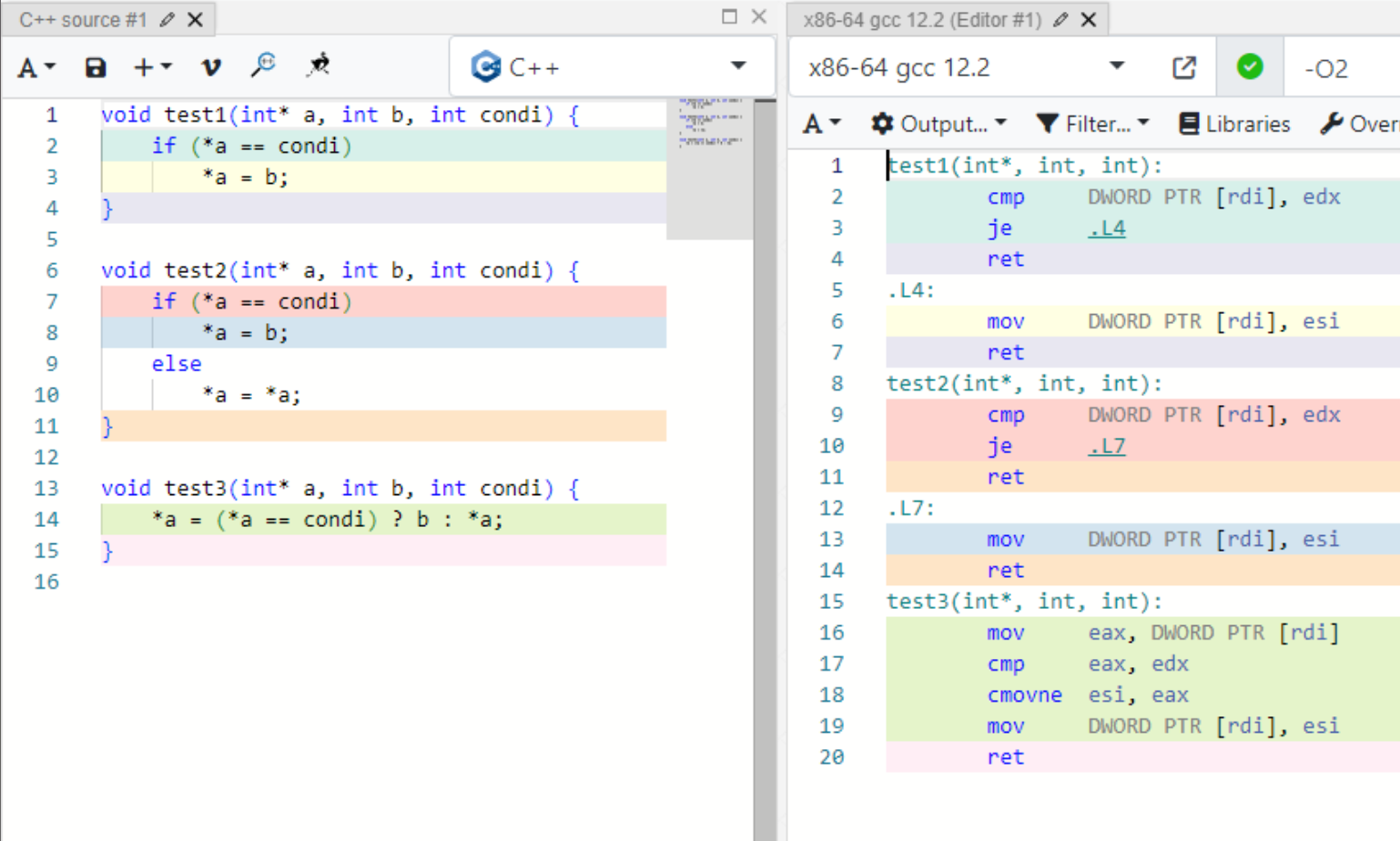
+ cmov 사용 방법
x64에서는 인라인어셈을 못쓰니 cmov를 직접적으로 사용할 순 없다.(intrinsic이나 attribute도 찾아보니 없음)
대신 삼항연산자를 사용하면 gcc와 msvc에서 branch를 사용하지 않고 cmov를 사용함을 확인했다.