
DB(SQLite?) 구현을 하던 중…
“음 이거 memory mapped file로 구현하면 되겠다.”
라고 생각하고 있었는데,
널리 쓰이는 상업 DB들은 memory mapped file이 아니라
그냥 block i/o(fwrite, fread) 로 구현한다는게 아니겠는가.
https://quasar.ai/memory-mapped-files-considered-harmful/
그래서 왜 그런지 보니…
memory mapped file의 문제는 다음과 같단다.
- 더티 페이지가 언제 디스크로 플러쉬 될지 알 수 없음. (트랙잭션 안전 보장이 힘듬)
- 엑세스하려는 데이터가 디스크에 있는지 램에 있는지 알 수 없음. (i/o wait)
- 성능이 오히려 떨어짐. (멀티스레드에서 확장이 힘듬)
ok. 1,2 번은 이해가 된다.
근데 3번.
성능이 오히려 떨어짐. (멀티스레드에서 확장이 힘듬)
??? 성능이 오히려 떨어진다고?
이해가 안되서 이것저것 자료를 다 찾아봤다.
http://library.kaist.ac.kr/search/detail/view.do?bibCtrlNo=237642&flag=t
https://ryotta-205.tistory.com/34
https://rntlqvnf.github.io/lecture%20notes/os-cache/
등등…
(전세계 기술 블로거 분들 사랑합니다.)
나 나름대로 취합하고 추측해 낸 내용은 다음과 같다.
- memory-mapped file을 쓰는 과정에서, DB는 거대하므로 page in/out이 반복될 것임.
- 이 과정에서 TLB entry가 바뀌어야 하므로 해당하는 entry를 수정/무효화 해야함.
이게 로컬 코어에서만 일어나는 일이면 문제가 별로 없다.
그런데 이게 멀티코어에서 작업하는 경우 문제가 생긴다. - 코어의 로컬 TLB만 수정하면 안 된다.
캐시 일관성과 비슷하게, 다른 모든 코어들에게 해당 TLB entry가 무효화 됐음을 브로드캐스트 해야한다.
(TLB shootdown) - 다른 코어가 해당 IPI(inter-processor interrupt)를 확인하고 TLB수정 후 ACK를 전송.
- Initiator 코어는 모든 ACK를 확인한 후 작업을 재개한다.
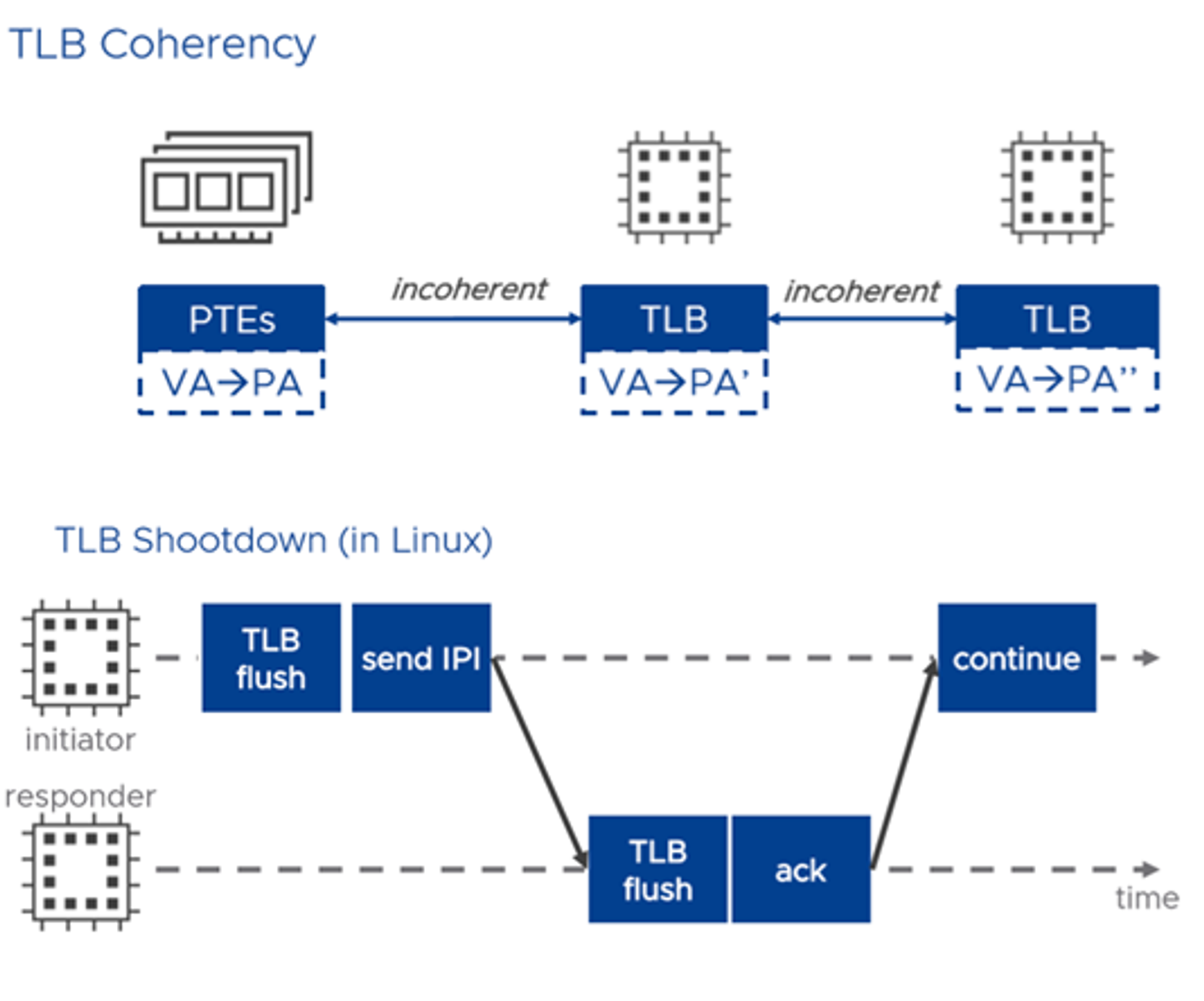 .
.
요약
멀티스레드 DB에서 memory mapped file을 사용하게 되면,
한 코어의 TLB entry가 변경될 시 다른 코어들에게 브로드캐스트 해야하고,(TLB shootdown)
다른 코어들의 ACK를 받아내야하는데 이 정보교환 루틴이 무진장 느리다.(busy wait)
그래서 안정성 & 성능 문제로 상업DB에선 MMIO를 안쓴다!!