
개요
국내에서 설명을 찾기 어려웠던 μops와 port 에 대해 설명할 것이다.
이를 위해 전체적인 파이프라인 과정을 보면서 진행하겠다.
아래 다이어그램은 Intel CPU의 파이프라인을 간략화한 다이어그램이다.
[1]https://uops.info/background.html
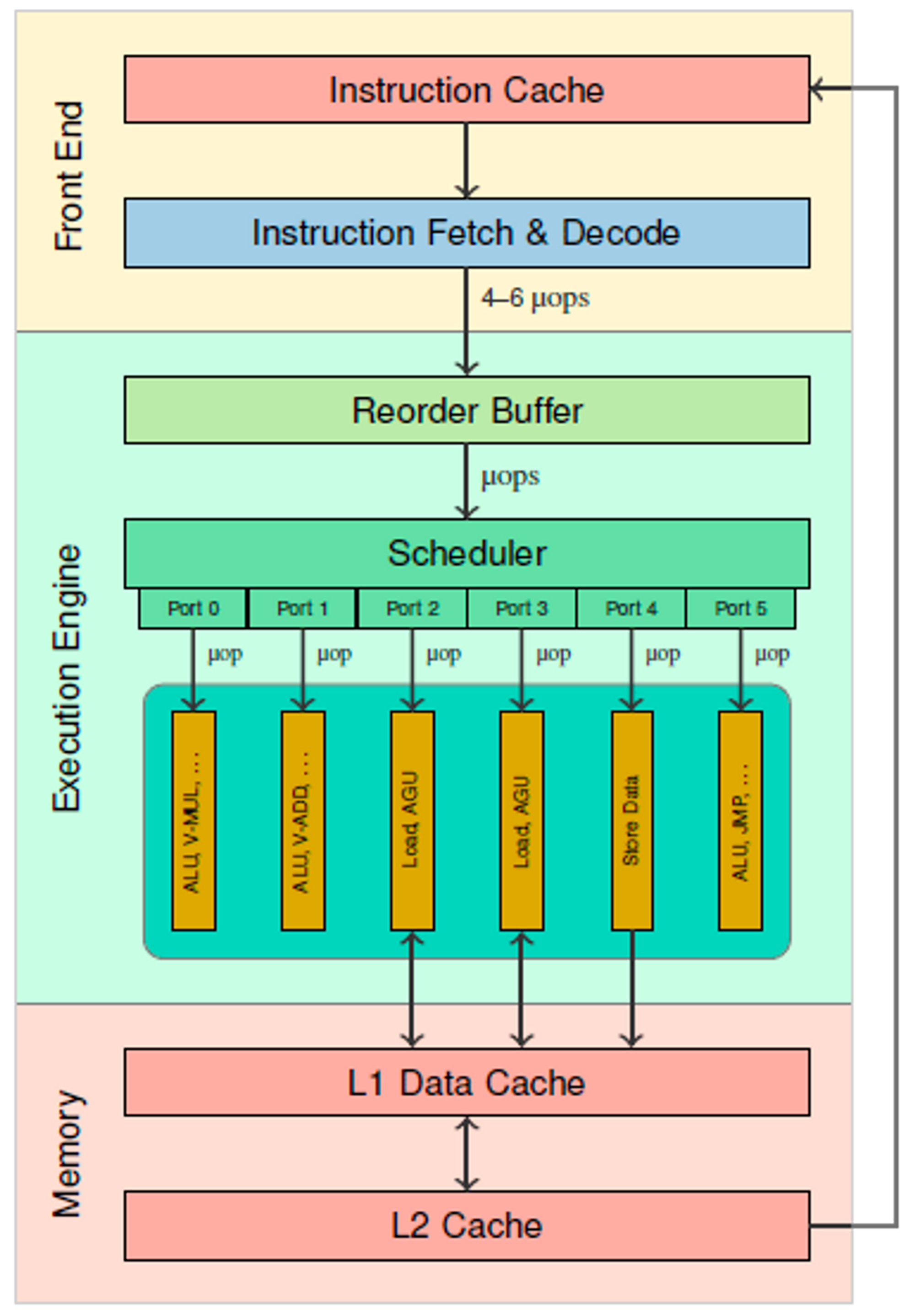
Fetch & Decode
CPU의 Front end에서는 캐시에서 명령어를 fetch한 뒤, decoder가 명령어의 해독을 수행한다.
명령어를 읽고 어떤 명령어인지, 피연산자는 몇 개인지, 명령어 길이는 몇인지를 파악하고
하나의 Instruction을 여러개의 μop(micro-operation) 으로 나누게 된다.
(macro-operation이란 개념도 있지만 생략)
예를 들어,
i++
이라는 연산은 다음과 같이 3개의 μop으로 분해될 수 있다.
load r0, [i]
add r0, 1
store [i], r0
즉 μop 이라는 것은 하나의 instruction을 cpu 내부 실행단위로 쪼갠 연산을 의미한다.
Scheduler & Port
decoder 에서 분해된 μop 들은 scheduler 로 보내진다.
(중간에 reorder buffer를 지나지만 이 글에서 out-of-order에 대해서 다루진 않을 것이므로 생략한다.)
scheduler는 μop 실행에 필요한 피연산자가 모두 준비되면,
Port라는 창구를 통해 Execution Unit으로 μop을 내보내 실행시키는 역할을 한다.
맨 위의 다이어그램을 보면,
Port 2 에는 Load, AGU 라는 실행유닛들이 연결되어 있다.
만약 scheduler가 메모리의 어떤 값을 load하는 μop을 실행시키고 싶다면,
해당 μop을 Port 2를 통해 실행유닛으로 전달한다.
그러면 load가 실행되는 동안 해당 μop이 port 2 와 port 2에 연결된 모든 실행유닛(load, AGU)을 점유한다.
이게 port 라는 개념이다.
하나의 μop은 하나의 port를 점유한다.
여러 μop이 동시에 실행될 때,
각각 실행되는 port가 다르다면 명령어는 병렬적으로 실행될 수 있다.
중간정리
μop과 scheduler port 에 대해 간략히 설명했다.
이젠 좀 더 디테일한 기능들과 응용에 대해 기술한다.
Port pressure
앞서 각각의 port는 병렬실행될 수 있다고 했다.
그러면 당연히 최대한 모든 port를 동시에 사용하는게 좋을것이다.
이와 관련해 매우 재밌는 문서를 찾았다.
https://www.intel.com/content/dam/doc/manual/64-ia-32-architectures-optimization-manual.pdf
551페이지
11.11.2 (Design Algorithm With Fewer Shuffles)
shuffle 연산은 skylake에서 오직 port 5 에서만 실행이 가능하다.
다른 포트는 shuffle 실행유닛이 없다.
위 문서에는 8x8 전치행렬을 구하는데 shuffle 24개를 사용해본다.
하지만 shuffle만 24개를 사용하면 port 5에만 압력이 강해지고 다른 포트는 노는 상황이 발생한다.
그래서 해결책으로 insert [mem]을 8개를 섞어
shuffle 16개, insert [mem] 8개로 port 5의 압력을 줄였더니
무려 70%(!!!)의 성능향상을 해냈다는 내용이다.
Port pressure 2 (about AGU on Port 7)
비슷한 내용이 또 있다.
하스웰-스카이레이크 아키텍쳐에서는 port 7에 AGU(Address Generation Unit)가 있는데,
여기 달려있는 AGU가 indexed address를 계산하지 못한다.
(159 페이지 11.12 https://www.agner.org/optimize/microarchitecture.pdf)
무슨 뜻이냐면..
mov [ebx+esi] // indexed address
mov [ebx] // non-indexed address
이 중에서 indexed address를 port 7에 있는 AGU가 유일하게 처리하지 못한다.
다른 포트에 있는 AGU를 사용해야 한다.
그래서 indexed addressing mode를 자제하는것이
잠재적으로 port 7까지 사용하여 성능향상을 기대할 수 있다.
uop-fusion (micro-fusion)
위에서
i++
이라는 연산은 다음과 같이 3개의 μop으로 분해될 수 있다고 했다.
load r0, [i]
add r0, 1
store [i], r0
하지만 이렇게 uop의 개수가 많으면 파이프라인 중간중간의 queue 슬롯이 많이 필요하고 관리하기 힘들다.
그래서 load-modify-store 순으로 사용되는 연산은 micro-fusion이라 하여
3개의 uop을 1개의 uop으로 융합해버린다.
(decoder의 부하를 줄이려는 목적도 있다)
그래서 i++ 연산은 load-modify-store 이므로 하나의 fused uop으로 표현될 수 있다.
물론 execution stage에서는 unfused되어 다시 3개의 uop으로 따로따로 포트에서 실행된다.
VSHUFPS vs VPERMILPS (uop-fusion advanced)
uop-fusion 의 예를 들어보겠다.
simd에서 vshuf와 vperm 명령이 있다.
permute는 로드+셔플 두 개의 연산을 하나의 명령어로 수행할 수 있지만
shuffle 명령어는 별다른 로드가 불가능하고 셔플만 연산이 가능하다.
//permute
vpermilps ymm0, [rdi], 0b00011011
//shuffle
vmovups ymm0, [rdi]
vshufps ymm0,ymm0,ymm0, 0b00011011
오 그러면 vpermilps가 당연히 한 줄에 끝나니 더 빠른것 아닌가.
싶지만 사실 실행속도는 똑같다.
왜냐하면 vpermilps는 memory operand + imm8 조합이라 micro-fusion이 불가능해 2uop이다.
shuffle의 경우는
vmovups 1uop, vshufps 1uop.
총 2uop이다.
즉 두 경우의 uop 개수가 동일하다.
명령어 바이트가 약간 차이나는 것 빼고 실행속도는 동일하다.
cpu 아키텍쳐마다 micro-fusion 조건이 다르니 이건 여러 메뉴얼을 참조하자.
uop-cache(DSB(Decoded Stream Buffer))
decode는 비용이 높다.
때문에 loop를 돌거나 하는 경우, 똑같은 decode를 수행해야 하므로 낭비로 이어진다.
그래서 붙인게 uop-cache이다. intel에서는 DSB라고 부른다.
캐시메모리와 거의 비슷하다고 이해하면 된다.
instruction 주소 하위비트를 룩업하여 엔트리로 사용한다.
cache-hit이면 decoder는 decode를 수행하지 않고 곧바로 scheduler에게 미리 해독된 μop을 내려보낸다.
LSD(Loop Stream Detector)
이건 uop-cache와 비슷하나 약간 다르다.
우선 자체 캐시를 가지고 있고, 이름 그대로 loop를 감지한다.
loop를 감지하면 decode과정을 생략하고 곧바로 자신이 들고있는 캐시의 uop을 사용한다.
이렇게 보면 DSB와 뭐가 다른가 싶지만
DSB는 decoder에 붙어있는것이고,
LSD는 decoder가 decode가 완료된 uop을 보내는 instruction queue에 내장되는 기능이다.
그래서 DSB보다 빠르고,
다만 캐시 크기가 작아서 타이트한 loop에만 동작할 수 있다.
여담 + 2023-09-09
뉴스에서 인텔이 cpu 버그에 대해 마이크로코드를 패치한다는 내용을 봤다.
decoder에서 uop이 어떻게 분해되거나,
어떻게 uop을 처리할지는 하드와이어가 아닌 프로그래머블하게 되어있는 모양이다.
이런 것 때문에 더더욱 DSB의 존재같은 것이 유용할 수 있을 것 같다.